Our proposed architecture SDFNet is able to successfuly reconstruct the shape from a single
image of object shape categories seen during training as well as new, unseen object categories.
SDFNet is trained to predict SDF values in the same pose as the input image without requiring knowledge of camera parameters or object pose at test time.
Qualitative results show superiority compared to baselines GenRe [1] and OccNet [2]
Seen Class

Input

SDFNet

OccNet

Ground Truth

Input

GenRe

Ground Truth
Novel Class

Input
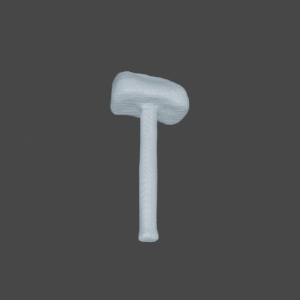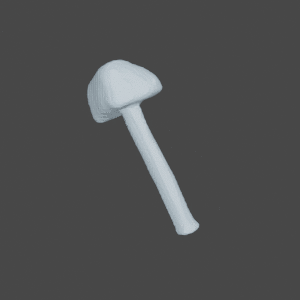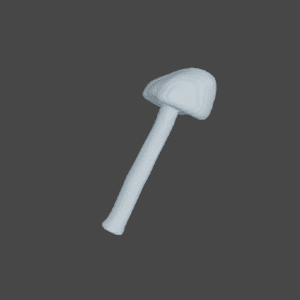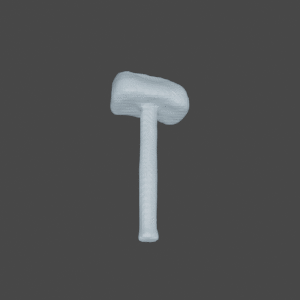
SDFNet

OccNet

Ground Truth

Input
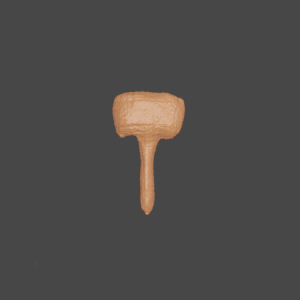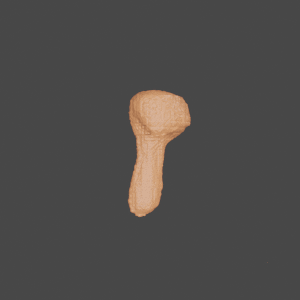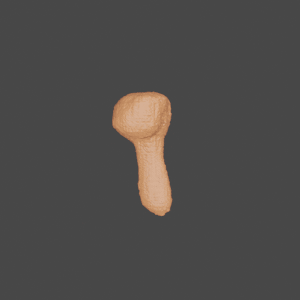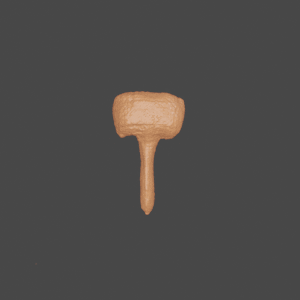
GenRe

Ground Truth
Novel Class

Input

SDFNet
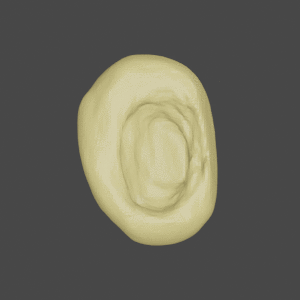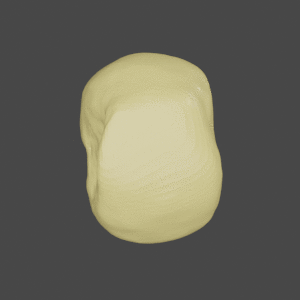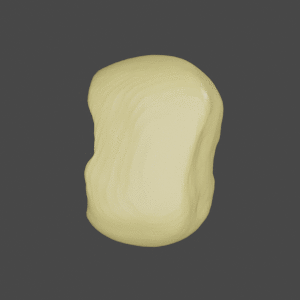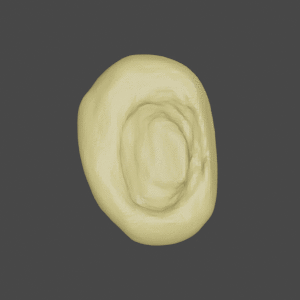
OccNet

Ground Truth

Input

GenRe

Ground Truth
Novel Class

Input

SDFNet

OccNet

Ground Truth

Input

GenRe

Ground Truth
Qualitative results of SDFNet, OccNet VC and GenRe on seen and unseen classes of 2 DOF ShapeNetCore.v2
Generalizing to Seen and Unseen Shapes
SDFNet is able to capture fine-grained details on the surface of seen classes (airplane example below) and infer occluded
surfaces of unseen categories (bathtub and camera). By explicitly estimating 2.5D sketches, SDFNet can capture concave surfaces (bathtub)
and protruding surfaces (camera lens).
Seen Class

Predicted

Ground Truth
Unseen Class

Predicted

Ground Truth
Unseen Class

Predicted

Ground Truth
SDFNet reconstruction performance on classes seen during training and novel classes not seen during training
Viewer Centered Training Affects Generalization
When evaluated on 3 Degree-of-Freedom Viewer Centered (3 DOF VC)—object pose varies along azimuth, elevation and tilt,
our empirical findings show marginal decrease in performance between seen and unseen classes for the 3 DOF VC model.
This is new evidence that it is possible to learn a general shape representation with correct depth estimation and 3 DOF VC training.
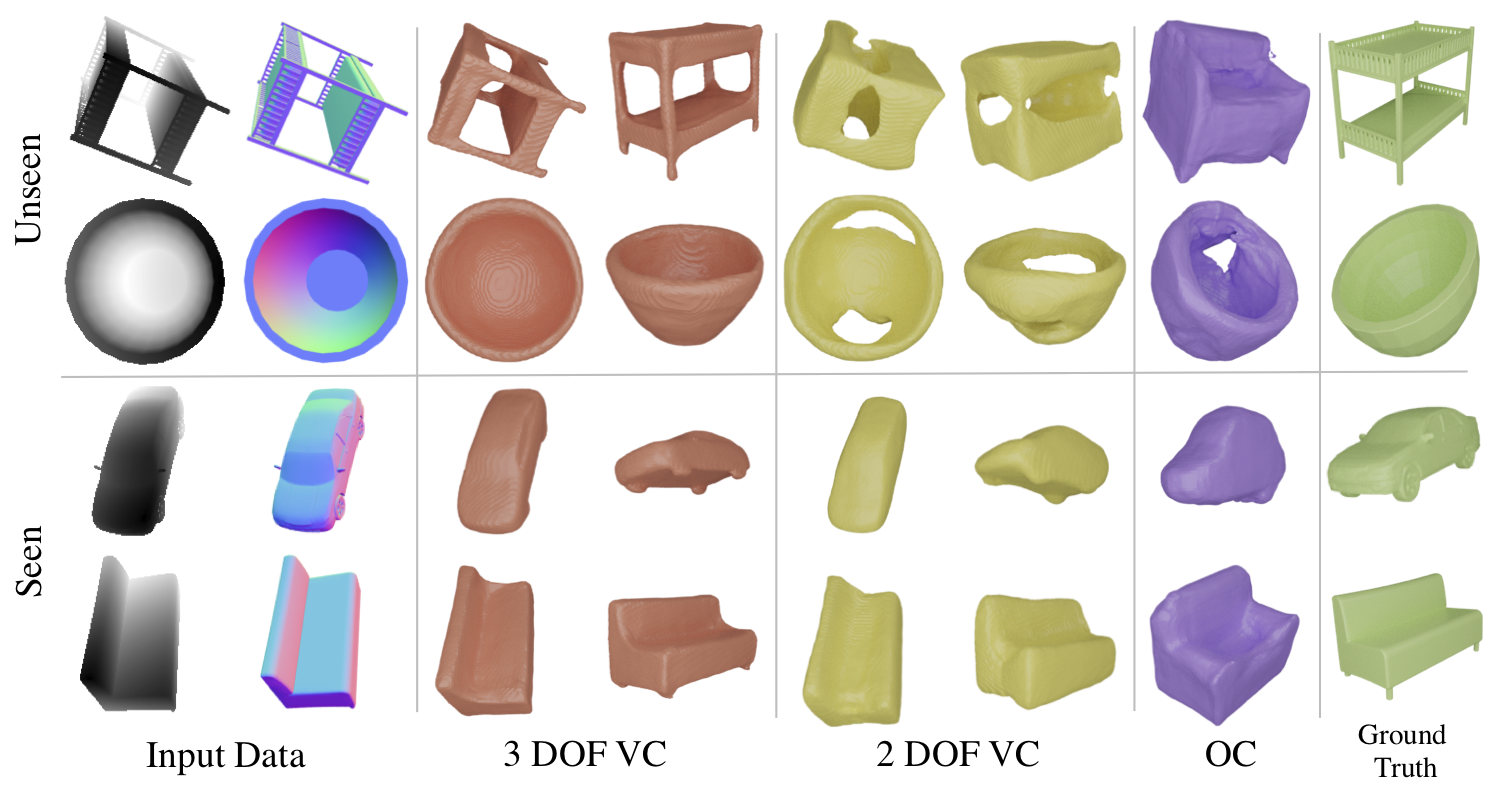
Quantitative evaluation of 3 DOF VC shows high performance on both seen and unseen categories. Model is trained on ground truth depth and normal images.
Generalization Across Different Datasets

Sample images of our renders of the four most common ShapeNet categories and of objects from ABC. It is evident that the two datasets have different shape properties.
To further test the generalization ability of SDFNet, we train it one one shape dataset and test it on a significantly different shape dataset. Our findings show that when trained on ABC and tested on the 42 unseen categories of ShapeNet, 3 DOF VC SDFNet obtains comparable performance to SDFNet trained on the 13 ShapeNet categories. SDFNet trained on ShapeNet performs relatively worse when tested on ABC.
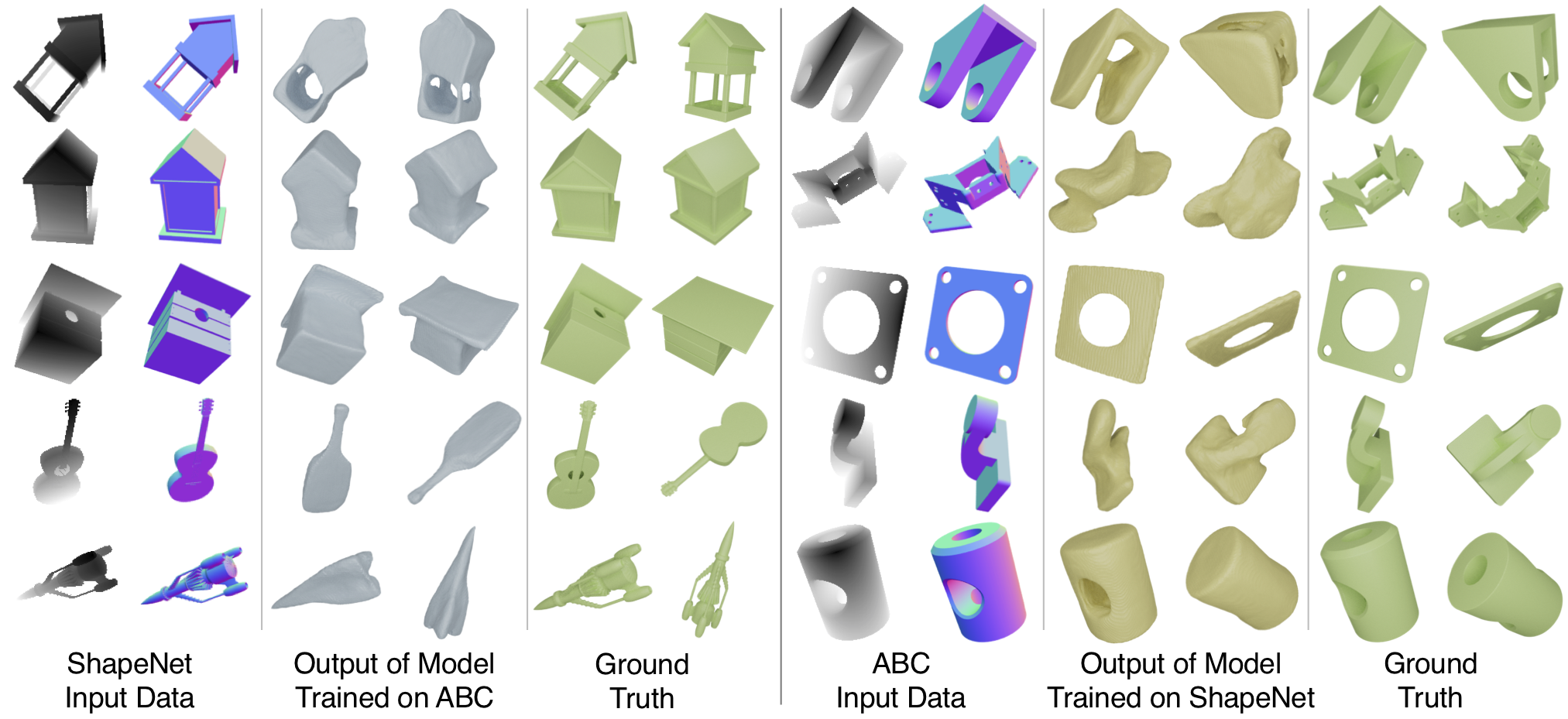
Qualitative comparison of models trained on ABC and tested on ShapeNet and vice-versa. Note the good reconstruction quality on the occluded part of the object.
Citation
Bibliography information of this work:
Thai, A., Stojanov, S., Upadhya, V., Rehg, J. (2020). 3D Reconstruction of Novel Object Shapes from Single Images. arXiv preprint:2006.07752.
References
- Zhang, X., Zhang, Z., Zhang, C., Tenenbaum, J., Freeman, B., & Wu, J. (2018). Learning to reconstruct shapes from unseen classes.
In Advances in Neural Information Processing Systems (pp. 2257-2268).
- Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., & Geiger, A. (2019).
Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 4460-4470).